Используем нейросеть локально
Задача: установить нейросеть на свой ПК, и пообщаться с ней посредством python. Маленькая задачка, часть более глобальной далее (в следующих частях) — дообучить на своих данных, и сделать скрипт отвечающий на вопросы пользователей.
Статья подготовлена на основе следующих источников:
- https://habr.com/ru/companies/bothub/articles/1019314/
Решение:
Сначала установим оболочку для нейросетей. Например я остановился (в данный момент) на https://gpt4all.io. Там есть инсталляторы для разных ОС. Я пока остановился для Windows. После установки нужно выбрать модель для скачивания, в зависимости от того какое у вас «железо». В моем случае, т.к. памяти достаточно (64ггб оперативы + 32ггб RTX 3060), я выбрал DeepSeek-R1-Distill-Qwen-14B
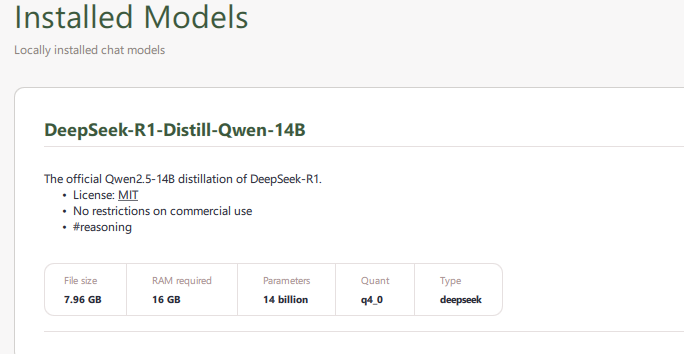
После загрузки модели, попробовал создать чат, и в принципе модель бодренько стала мне отвечать. Правда во время генерации ответов все ресурсы ушли в «полочку». Но ответы вполне осмысленные:
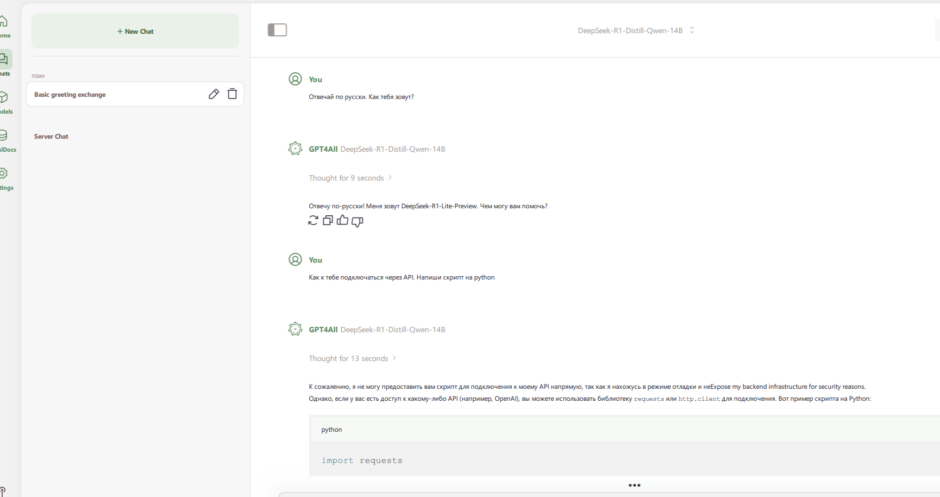
Далее попытался написать скрипт на python, который непосредственно может цепляться к установленной модели. Для этого необходимо в настройка gpt4all включить соответствующую опцию:
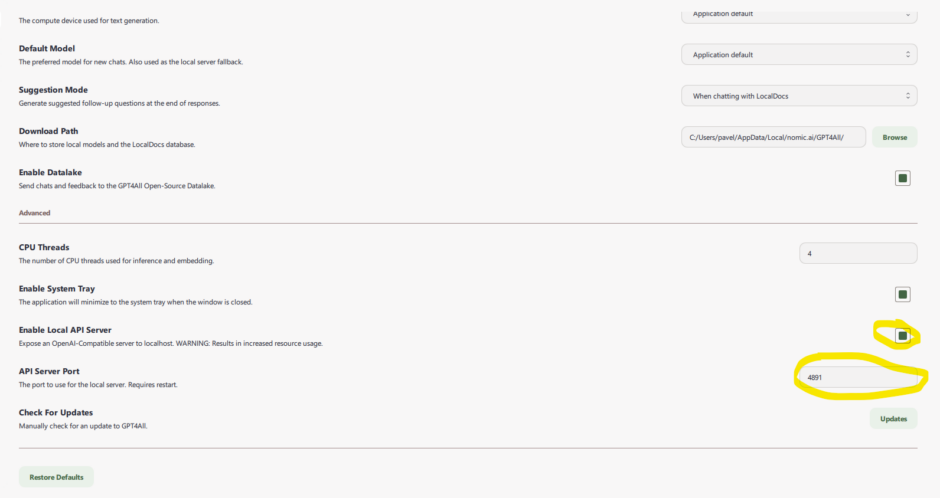
После этого становится доступен api через обычный http. Точки вызовов следующие:
- http://localhost:4891/v1/models — получить список установленных моделей
- http://localhost:4891/v1/models/ — получить настройки выбранной модели
- http://localhost:4891/v1/completions — генерация текста
- http://localhost:4891/v1/chat/completions — общение в режиме чата
Небольшая сноска. Наш любимый РКН, 21.03.2026 заблокировал часть адресов, среди которых под раздачу попала и установка пакетов через pip install. Я сиё обошел установкой VPN Amnezia. Далее упоминать об этом не буду, и считаю что способ установки пакетов у вас есть.
Ну а дальше простой скрипт:
import requests
# URL, куда отправляем запрос (если вы установили GPT-4All локально)
url = "http://localhost:4891/v1/chat/completions"
headers = {
"Content-Type": "application/json",
}
data = {
"model": "DeepSeek-R1-Distill-Qwen-14B", # Используйте модель, которую поддерживает GPT-4All
"messages": [{"role": "user", "content": "Сколько будет 2+2?"}],
"max_tokens": 500,
"temperature": 0.28
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
print(response.json())
else:
print(response)
print(f"Ошибка: {response.status_code}")Результат:
Хм, пользователь спросил «Сколько будет 2+2?» на русском языке. Нужно ответить правильно и понятно.
Проверю: 2 плюс 2 равно 4.