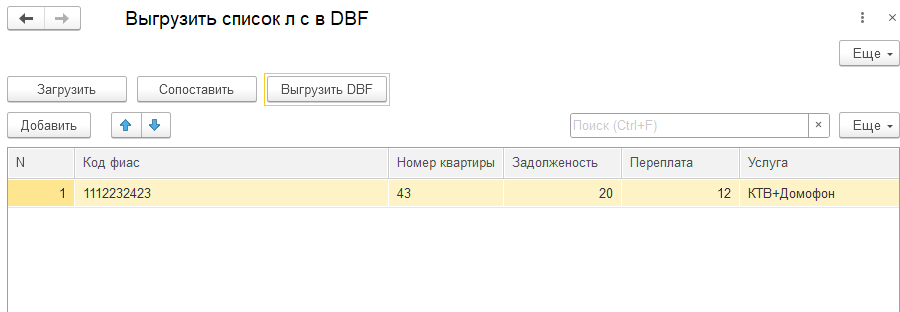
Создание файла формата DBF в 1С
Задача: создать силами платформы 1c файл в формате DBF (выгрузка в формате dbf)
Решение: собственно в 1С всё есть. Будем использовать метод XBase. При работе с DBF важно помнить, что это очень старый формат хранения данных, но тем не менее до сих пор используется для различного вида обменов. Его ограничениями являются:
- длина имени файлов не более 8 символов, поэтому при генерации имени временного файла, не получится использовать функцию ПолучитьИмяВременногоФайла()
- файл не должен быть больше 2ггб
- имя колонки не может быть длиннее 10 символов
- файл создается НЕ в кодировке UTF-8 (он в такую не умеет)
- файл нужно сначала создать, потом закрыть, потом открыть и записать в него данные
А так, файл создаётся достаточно просто:
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
объект.РезультирующиеДанные.Очистить();
нс=объект.РезультирующиеДанные.Добавить();
нс.Код_фиас="1112232423";
нс.НомерКвартиры="43";
нс.Задолженость="20";
нс.Переплата="12";
нс.Услуга="КТВ+Домофон";
нс.ЛС_База="235465";
нс.ЛС_ЕПД="223234234";
нс.ЛС_Электрика="445457223";
нс.Адрес="г. Вологда,ул Лёнина 3";
нс.АдресДоставки="г. Сокол, ул Лёнина 4";
КонецПроцедуры
&НаСервере
Функция ВыгрузитьDBFНаСервере()
answer=Новый Структура("хранилище,имяфайла");
НоваяТаблица = Новый XBase;
НоваяТаблица.Кодировка = КодировкаXBase.ANSI;
НоваяТаблица.Поля.Добавить("fias","S",50);
НоваяТаблица.Поля.Добавить("flat","S",10);
НоваяТаблица.Поля.Добавить("credit","N",10,2);
НоваяТаблица.Поля.Добавить("debet","N",10,2);
НоваяТаблица.Поля.Добавить("service","S",50);
НоваяТаблица.Поля.Добавить("ls_base","S",10);
НоваяТаблица.Поля.Добавить("ls_epd","S",10);
НоваяТаблица.Поля.Добавить("ls_electro","S",10);
НоваяТаблица.Поля.Добавить("address","S",100);
НоваяТаблица.Поля.Добавить("delivery","S",100);
имя_фр_файла=Лев(Новый УникальныйИдентификатор(),8)+".dbf";
ПутьКНовомуDBF = КаталогВременныхФайлов()+"/"+имя_фр_файла;
НоваяТаблица.СоздатьФайл(ПутьКНовомуDBF);
НоваяТаблица.ЗакрытьФайл();
Таблица = Новый XBase;
Таблица.ОткрытьФайл(ПутьКНовомуDBF,, Ложь);
для каждого стр из объект.РезультирующиеДанные цикл
Таблица.Добавить();
Таблица.fias = стр.Код_фиас;
Таблица.credit = стр.НомерКвартиры;
Таблица.debet = стр.Задолженость;
Таблица.service = стр.Переплата;
Таблица.ls_base = стр.Услуга;
Таблица.ls_epd = стр.ЛС_База;
Таблица.ls_electro = стр.ЛС_ЕПД;
Таблица.address = стр.address;
Таблица.delivery = стр.АдресДоставки;
Таблица.Записать();
конеццикла;
Таблица.ЗакрытьФайл();
Двоичное=Новый ДвоичныеДанные(ПутьКНовомуDBF);
answer.хранилище=ПоместитьВоВременноеХранилище(Двоичное,ЭтаФорма.УникальныйИдентификатор);
answer.имяфайла=имя_фр_файла;
возврат answer;
КонецФункции
&НаКлиенте
Процедура ВыгрузитьDBF(Команда)
рез=ВыгрузитьDBFНаСервере();
Двоичное=ПолучитьИзВременногоХранилища(рез.хранилище);
ИмяФайла = КаталогВременныхФайлов() + рез.имяфайла;
Двоичное.Записать(ИмяФайла);
ЗапуститьПриложение(ИмяФайла);
КонецПроцедуры