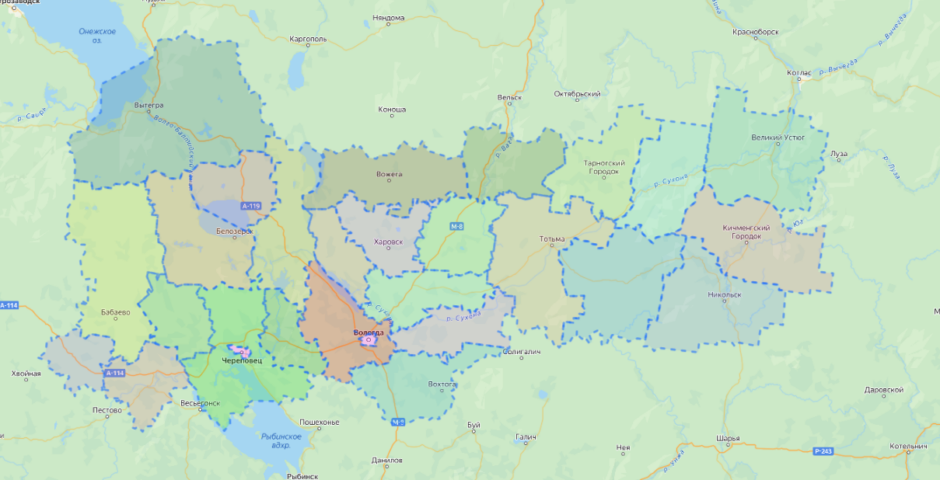
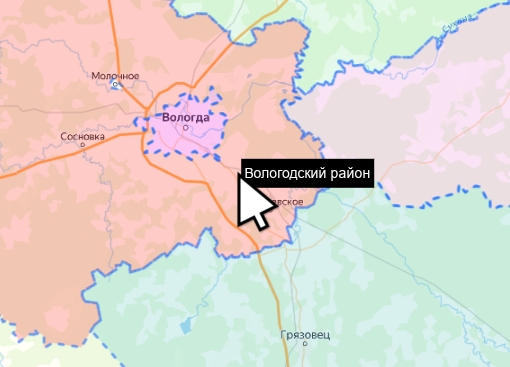
Map API Yandex 3: Подсказки при наведении на полигон
Нет, всё таки версия 3 еще сыровата для внедрения в прод. Ну или «лыжи не едут». Для решения простой задачи — отображение подсказки над полигоном, пришлось переписываться с тех поддержкой яндекса (и они даже ответили!, чем я безмерно удивлён). В результате родился скрипт, в котором требуется переопределение вызовов класса. Хм.. это определенно не то что хочется видеть для получения базовых вещей, которые в версии 2.1 работают «из коробки».
async function main() {
await ymaps3.ready;
ymaps3.import.registerCdn('https://cdn.jsdelivr.net/npm/{package}',['@yandex/ymaps3-hint@0.0.1']);
const {YMap,YMapDefaultSchemeLayer,YMapFeature,YMapDefaultFeaturesLayer,YMapFeatureSource,YMapFeatureDataSource,YMapEntity} = ymaps3;
const {YMapHint,YMapHintContext} = await ymaps3.import('@yandex/ymaps3-hint');
map = new ymaps3.YMap(
document.getElementById('app'),
{location:
{
center: [39.8491648, 59.2084992],
zoom: 9
},
showScaleInCopyrights: false //шкала масштаба рядом в логотипом
}
);
const defaultScheme = new YMapDefaultSchemeLayer({}); // Добавляем рисованное изображение карты
map.addChild(defaultScheme);
const features = new YMapDefaultFeaturesLayer();
map.addChild(features);
//получаем список районов
common.AjaxPost("index.php?r=site2/get-areas","").then(async areas_list=>{
console.log("-прочитал список районов ",areas_list);
if (areas_list.error==false){
for (var i = 0; i < areas_list.result.length; i++) {
await common.AjaxPost("areas/"+areas_list.result[i].poly_filename,"aa").then(res2=>{
console.log(areas_list.result[i].name);
res2=common.ReverseCoors(res2);
console.log(areas_list.result[i].poly_fill_color);
const polygon = new ymaps3.YMapFeature({
geometry: {
type: 'Polygon',
coordinates: res2
},
properties: {
hint: areas_list.result[i].name+" район"
},
style: {
stroke: [
{
color: '#196DFF99',
dash: [5, 10],
width: 3
}
],
fillOpacity: 0.2,
fill: "#"+areas_list.result[i].poly_fill_color
}
});
features.addChild(polygon);
});
};
};
});
const hint = new YMapHint({
layers: [features.layer],
hint: object => object?.properties?.hint
});
map.addChild(hint);
hint.addChild(
new(
class MyHint extends YMapEntity {
_onAttach() {
this._element =document.createElement('div');
this._element.className ='hint';
this._detachDom =ymaps3.useDomContext(this,this._element);
this._watchContext(
YMapHintContext,
() => {
const context =this._consumeContext(YMapHintContext);
this._element.textContent =(context?.hint || '');
console.log(this._element);
}, {
immediate: true
}
);
}
_onDetach() {this._detachDom();}
}
)()
);
};
window.map = null;
main();