Продолжаем начатое. Добавим в игру увеличение скорости если питон ест, и подсчет очков. Добавим переменные:
...
speed=500; # начальная скорость питона
increase_speed=10; # размер увеличения скорости при удачной еде
score=0; # набранные очки в результате игры
score_color=(100,100,50) # цвет очков
...
Интересный момент работы с таймером. По умолчанию time.time() отдает данные в секундах целые числа, и доли секунд в цифрах после запятой. Для того чтобы соответственно удобно считать миллисекунды, значения нужно умножать на 1000. Изменим код:
start_time=time.time()*1000
...
while running:
if (time.time()*1000-start_time)>speed:
start_time=time.time()*1000
Draw_foods(screen)
Draw_python(screen)
...
А теперь изменим функцию Draw_python, добавив отрисовку количества очков, а так-же увеличение скорости и количества очков при поедании:
...
global score,speed
..
for element in foods:
if [element[0],element[1]] == head_coor:
del_tail=False
foods.remove(element)
speed=speed-increase_speed # увеличиваем скорость питона
score=score+element[0] # увеличиваем очки в зависимости от типа сожранного
...
# Рисую набранные очки
pygame.draw.rect(screen,(0,0,0),(width_field,0,width_field+300,100))
img = font.render(f'Очки: {score}', True, score_color)
screen.blit(img, (width_field+10, 20))
...
Добавим еще штрих — сделаем реакцию на столкновение со стенами поля, а именно чтоб питон переходил на левый край при столкновении с правым и т.д.,
... if (head_coor[0]>size_x):
head_coor[0]=1;
if (head_coor[1]>size_y):
head_coor[1]=1;
if (head_coor[0]<0):
head_coor[0]=size_x;
if (head_coor[1]<0):
head_coor[1]=size_y;
...
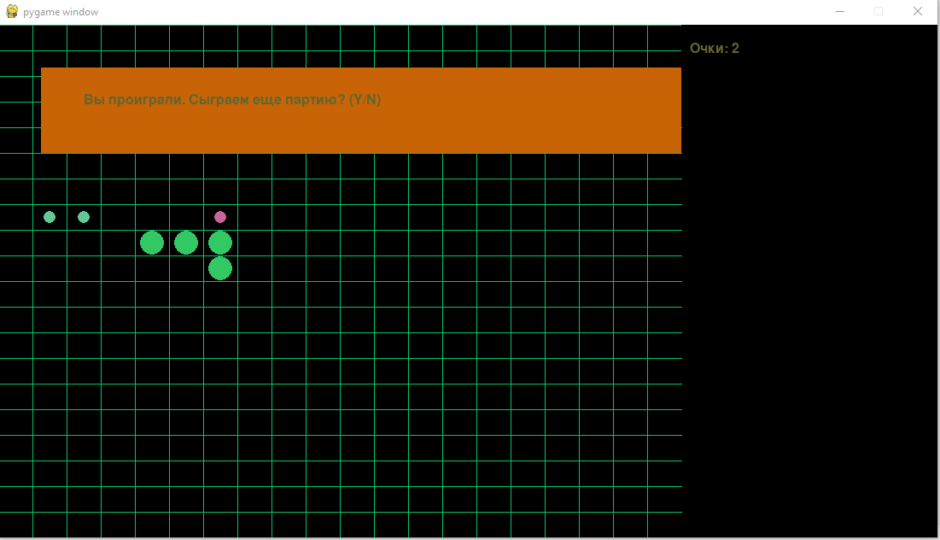
Теперь не хватает последнего: проигрыша в случае столкновения головы с хвостом. Объявим глобальный цикл в котором будет крутится игра, в нём разместим цикл игры. При проигрыше выводим вопрос «Вы проиграли хотите еще (Y/N)» Если игрок выбирает Y, то из глобального цикла не выходим, иначе покидаем глобальный цикл.
gloop=True
while gloop: # глобальный цикл
pygame.init()
...
font = pygame.font.SysFont(None, 24)
while running: # цикл игры
if (time.time()*1000-start_time)>speed:
start_time=time.time()*1000
...
# здесь оказываемся когда проиграли...
pygame.draw.rect(screen,(200,100,5),(50,50,width_field-50,100))
img = font.render(f'Вы проиграли. Сыграем еще партию? (Y/N)', True, score_color)
screen.blit(img, (100, 80))
pygame.display.flip()
pygame.display.update()
running = True
while running:
for event in pygame.event.get():
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_y:
moved_direction_x = 0
moved_direction_y = 0
speed=500
score=0
gloop=True
running=False
if event.key == pygame.K_n:
gloop=False
running = False
print("нормально вышли")
Окончательную версию игры можно скачать здесь