Хотя в любом другом дистрибутиве получаю стандартное:
Начал рыть….долго и упорно… искал разницу между установленными версиями curl. И единственное что по большому счёту отличало версию Astra Linux — поддержка сертификатов шифрования ГОСТ. А сайт Госуслуг именно их и использует. Причем шифрование на этом сайте версии 1.3. А что если попробовать принудительно попросить curl именно это шифрование? И в правду заработало:
Что вы ожидаете увидеть в выводе? 115? А вот и нет. Если echo выведет 115, то var_dump выведет 114.99999
Что не так с float?
Тип float в языке PHP, как и его “родственник” тип double, вовсе не предназначен для точного представления десятичных дробей. Всё что мы записали в float, хранится в приближенном значении, с некоторой погрешностью.
Решение: в виду того что в PHP это считается фичей, а не багом, то для точной работы с математикой нужно использовать модуль bcmath. Ну или использовать округления до нужной точности
Задача: Есть некая очень захламленная сторонними элементами страница в разметке html. Необходимо преобразовать находящуюся на ней таблица в массив данных.
Решение: сначала вычленим «грязное» содержимое таблицы между тегами <tbody></tbody>, затем преобразуем его в DOM документ, а далее уже распарсим его обходами и разложим элементы в массив.
Получилось что-то вроде:
//вычленяю таблицу
$t1=explode("<tbody>",$res);
$t2=explode("</tbody>",$t1[1]);
$tbody="<html><head><meta charset='UTF-8'></head><body><table><tbody>".$t2[0]."</tbody></table></body></html>";
$mass=[];
$dom = new domDocument('1.0', 'utf-8');
@$dom->loadHTML($tbody);
$tables= $dom->getElementsByTagName('table');
foreach ($tables as $table) {
$trs= $table->getElementsByTagName('tr');
foreach ($trs as $tr) {
$tds=$tr->getElementsByTagName('td');
$info=[];
foreach ($tds as $td) {
$info[]=$td->textContent;
};
$mass[]=$info;
}
}
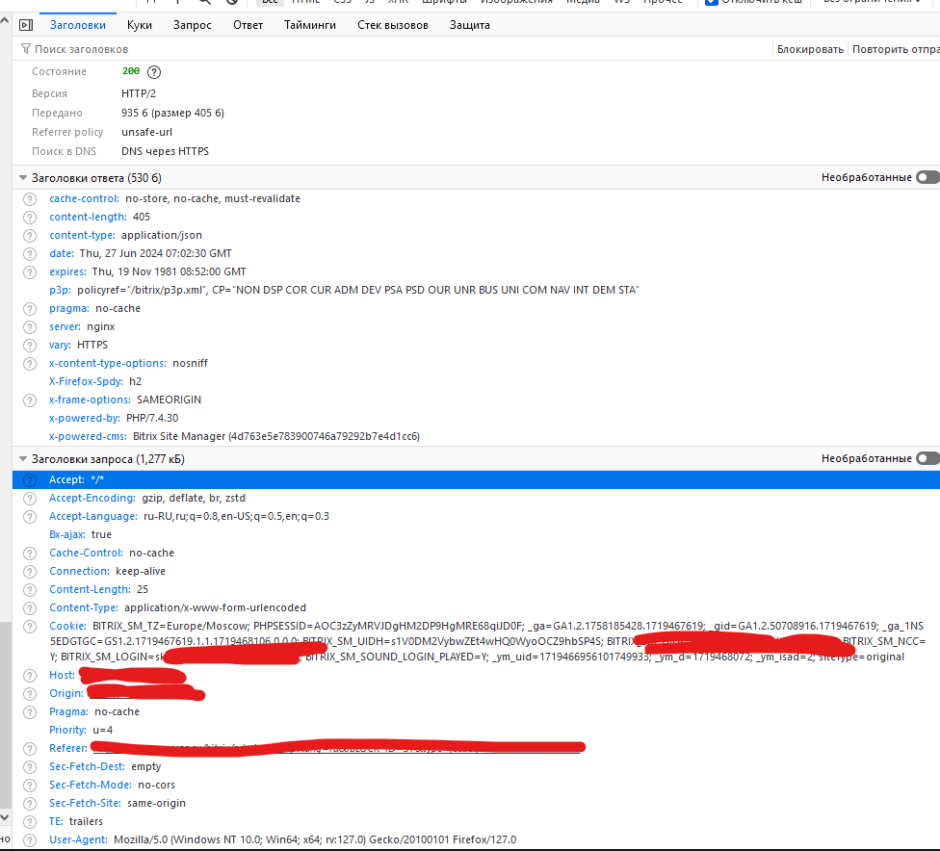
В одном из проектов, скрипт парсит сайт на bitrix. С какого то момента, при установке параметров таблицы отдаваемой по ajax, стала выводиться ошибка «Request is not XHR». Быстрый гуглинг решения не дал. Стал кропотливо сравнивать заголовки которые отдаются запросом в браузере и заголовки который отдавал в скрипте. Отличие нашлось относительно быстро, страница на сайте добавляла дополнительный заголовок «Bx-ajax:true». В результате модифицировал скрипт следующим образом:
Для начала прочитаем содержимое архива (чтение архива zip на php). Во встречающихся на просторах интернета примерах, зачастую игнорируется тот факт, что имена файлов могут быть в кириллице.В результате пользователи видят «крякозябры». А zip хранит имена файлов, указывая их не в кодировке UTF-8, а в кодировке cp866 (видимо из соображения совместимости). По крайне мере на Windows. Поэтому имена файлов перед употреблением, нужно переформатировать в UTF-8.