При стандартной установке веб сервера на astra linux, после запуска сервиса apache, в браузере по адресу localhos всегда будем получать ошибку в логах «authentication not configured». Решением является добавление в /etc/apache2/apache2.conf тега:
В PHP версиях до 7.1, в некоторых скриптах используется команда Eval, позволяющая выполнить переданный на входе текст, как команду PHP. В последующих версия PHP, данная команда помечена как Deprecated. При апргрейде, соответственно часть скриптов перестают работать. Вот моё решение по замене:
function eval($str){
file_put_content("tmp.php",$str);
include 'tmp.php';
}
P.S. Совсем если честно не понял зачем было удалять эту команду из за «безопасности», если тому кому нужно вполне заменят её подобным костылём как у меня. Моё мнение: любое обновление не должно ломать старый код, исключения — крайние случаи. Этот случай явно не крайний.
Задача: загрузить в табличный документ на форме файл большого размера, с индикацией прогресса загрузки с использованием фоновой работы.
Решение: если поддержка фоновой работы в 1С была уже довольно давно, то асинхронная загрузка файлов на сервер появилась лишь начиная с версии 8.3.15.1489 ,Ну тоже уже давно, но руки добрались начать использовать только сейчас, т.к. ранее было не критично — не настолько большие файлы загружал/обрабатывал.
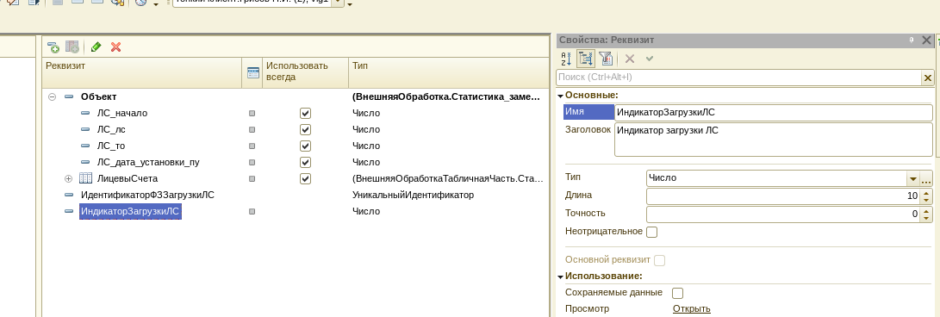
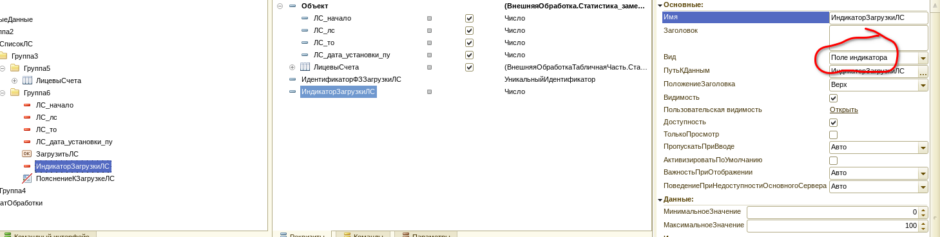
Итак, сначала на форме разместим индикатор загрузки. Для этого в реквизитах формы необходимо создать переменную типа «число», и перетащив её на форму выбрать тип «индикатор»:
На кнопку «Загрузить ЛС» навесим открытие диалогового окна:
Фильтр = "Файл с лицевыми счетами(*.xlsx)|*.xlsx";
ПараметрыДиалога = новый ПараметрыДиалогаПомещенияФайлов("Выберите файлы XLSX", Истина, Фильтр);
А чуть ниже определим обработчики оповещения о ходе загрузки файла на сервер и окончании загрузки файла, которые укажем при вызове процедуры «НачатьПомещениеФайлаНаСервер» (есть еще и «НачатьПомещениеФайловНаСервер»). В итоге код получится такой:
В результате чего после выбора файла, по экрану побежит индикатор хода перемещения файла на сервер. Далее этот файл необходимо будет обработать на сервере фоново. И тут возникает один нюанс: мы не можем передать в фоновое задание ссылку на перемещенный файл во временном хранилище.Точнее можем, но фоновое задание это хранилище прочитать не может (это то ли глюк, то ли фича платформы — не понятно). Проблема.. Тогда делаем финт ушами: перед уходом в «фон», мы создадим временный файл во временной папке пользователя 1С, и передадим в фон уже не ссылку на него, а непосредственно имя временного файла. Для этого я просто написал функцию, которая на входе получает адрес загруженного файла, а на выходе даёт имя временного файла:
Кроме того, чтобы мы могли передать результат в обработку по завершению фоновой работы, нам необходимо при запуске фонового задания передать в него некоторые параметры, а именно:
имя созданного временного файла
колонки/строки откуда брать данные из эксель файла
адрес временного хранилища, куда поместить результат работы фонового задания
Функция которая будет работать фоново, должна размещаться в общем модуле. Это небольшой недостаток внешних обработок — фоново запускаются только процедуры-функции созданные внутри конфигурации. Но! до этого нам нужно опять же написать «обвязку» фонового задания, дабы мы имели возможность знать, работает или нет оно, а так-же на каком этапе. При запуске фонового задания, мы получаем идентификатор этого задания:
Функция ЗапуститьФЗЗагрузкиЛС(Параметры)
МассивПараметров = Новый Массив;
МассивПараметров.Добавить(Параметры);
ФЗ = ФоновыеЗадания.Выполнить("СК_ГР_ДлительныеОперации.ЗагрузитьФайлыЛС",МассивПараметров);
объект.ЛС_ФЗ = ФЗ.УникальныйИдентификатор;
КонецФункции
Который в дальнейшем будем использоваться для того чтобы «узнать» как поживает собственно это задание, подключив на клиенте обработчик ожидания, выполняющийся раз в секунду:
&НаКлиенте
Процедура ИндикаторВыполненияЗагрузкиФайловЛС() Экспорт
пр=КакДелаУФЗЗагрузкиФайловЛС();
если пр=неопределено тогда
этаформа.ИндикаторЗагрузкиЛС=100;
ОтключитьОбработчикОжидания("ИндикаторВыполненияЗагрузкиФайловЛС");
Этаформа.Элементы.ПояснениеКЗагрузкеЛС.Заголовок="Файлы обработаны";
иначе
этаформа.ИндикаторЗагрузкиЛС=пр;
конецесли;
КонецПроцедуры
&НаСервере
Функция КакДелаУФЗЗагрузкиФайловЛС()
ФЗ = ФоновыеЗадания.НайтиПоУникальномуИдентификатору(объект.идФЗ);
если ФЗ=Неопределено тогда
возврат неопределено;
иначе
если ФЗ.Состояние=СостояниеФоновогоЗадания.Завершено тогда
возврат неопределено;
конецесли;
если ФЗ.Состояние=СостояниеФоновогоЗадания.ЗавершеноАварийно тогда
Сообщить("Ошибка:"+ФЗ.ИнформацияОбОшибке.Описание);
возврат неопределено;
конецесли;
конецесли;
возврат 0;
конецфункции
Как видим, тут отслеживается состояние фонового задания (запущен, работает, завершен, завершен с ошибкой), но не отслеживается этап выполнения работ. Есть на самом деле два способа получения хода работы фонового задания:
перехват вывода функции Сообщить() на сервере, и парсинг данных из него. Например в фоновом задании можно с какой-то периодичностью выводить что-то вроде: Сообщить(«12.3%загружаю»);, а получив на клиенте эту запись показывать индикацию 12.3% и соответствующее пояснение.
Можно во время работы фонового задания ложить данные во временно хранилище, и читать их из клиента. НО! данный способ работает только в случай файловой БД. Циатата из справки 1С: «Данные, помещенные во временное хранилище в фоновом задании, не будут доступны из родительского сеанса до момента завершения фонового задания»
Посему остаётся таки отлавливать сообщения сервера по известному идентификатору фонового задания:
&НаСервере
Функция ПолучитьСообщенияФЗ(ФЗ, Состояние = Неопределено, УдалятьСообщения = Ложь) Экспорт
Если Состояние = Неопределено Тогда
Состояние = ФЗ.Состояние;
КонецЕсли;
МассивСообщений = Новый Массив;
Сообщения = ФЗ.ПолучитьСообщенияПользователю(УдалятьСообщения);
Если Сообщения <> Неопределено Тогда
Для Каждого Сообщение Из Сообщения Цикл
МассивСообщений.Добавить(Сообщение.Текст);
КонецЦикла;
КонецЕсли;
Возврат МассивСообщений;
КонецФункции
А в самом фоновом здании, городить огород с выводом сообщений:
// На входе:
// парам.ВременныйФайл
// парам.Расширение
// парам.ЛС_начало
// парам.ЛС_лс
// парам.ЛС_то
// парам.ЛС_дата_установки_пу
// парам.АдресВременногХранилища
Функция ЗагрузитьФайлыЛСРасширенно(парам) экспорт
Сообщить("0%читаю файл на сервере");
ТабличныйДокументХар = Новый ТабличныйДокумент;
ТабличныйДокументХар.Прочитать(парам.ВременныйФайл,СпособЧтенияЗначенийТабличногоДокумента.Значение);
стар=0;
Для Каждого ОбластьТД ИЗ ТабличныйДокументХар.Области Цикл
ОбластьФайла = ТабличныйДокументХар.ПолучитьОбласть(ОбластьТД.Имя);
КолВоСтрокФайла = ОбластьФайла.ПолучитьРазмерОбластиДанныхПоВертикали();
КолВоКолонокФайла = ОбластьФайла.ПолучитьРазмерОбластиДанныхПоГоризонтали();
НачСтрока=парам.ЛС_начало;КонСтрока=0;
НачСтрока = ?(НачСтрока = 0, 2, НачСтрока);
КонСтрока = ?(КонСтрока = 0, КолвоСтрокФайла, КонСтрока);
//перебираем все строки без первой строки
Для нСтрокаТФ = НачСтрока ПО КонСтрока Цикл
если стар<>Окр(нСтрокаТФ*100/КонСтрока) тогда
Сообщить(Строка(Окр(нСтрокаТФ*100/КонСтрока))+"%обрабатываю файл");
стар=Окр(нСтрокаТФ*100/КонСтрока);
конецесли;
конеццикла;
конеццикла
конецфункции
Посему модифицируем и обработчик ожидания, добавив парсинг сообщений сервера:
&НаКлиенте
Процедура ИндикаторВыполненияЗагрузкиФайловЛС() Экспорт
пр=КакДелаУФЗЗагрузкиФайловЛС();
если пр=неопределено тогда
этаформа.ИндикаторЗагрузкиЛС=100;
ОтключитьОбработчикОжидания("ИндикаторВыполненияЗагрузкиФайловЛС");
Этаформа.Элементы.ПояснениеКЗагрузкеЛС.Заголовок="Файлы обработаны";
иначе
если пр.Количество()>0 тогда
этаформа.ИндикаторЗагрузкиЛС=пр[0];
Этаформа.Элементы.ПояснениеКЗагрузкеЛС.Заголовок=пр[1];
конецесли;
конецесли;
КонецПроцедуры
&НаСервере
Функция КакДелаУФЗЗагрузкиФайловЛС()
ФЗ = ФоновыеЗадания.НайтиПоУникальномуИдентификатору(объект.ЛС_ФЗ);
если ФЗ=Неопределено тогда
возврат неопределено;
иначе
если ФЗ.Состояние=СостояниеФоновогоЗадания.Завершено тогда
возврат неопределено;
конецесли;
если ФЗ.Состояние=СостояниеФоновогоЗадания.ЗавершеноАварийно тогда
Сообщить("Ошибка:"+ФЗ.ИнформацияОбОшибке.Описание);
возврат неопределено;
конецесли;
ФСообщения=СК_ГР_ДлительныеОперации.ПолучитьСообщенияФЗ(ФЗ,,истина);
Если ФСообщения.Количество() > 0 Тогда
Для Каждого Сообщение Из ФСообщения Цикл
Если СтрНайти(Сообщение,"%")>0 тогда
возврат СтрРазделить(Сообщение,"%");
конецесли;
КонецЦикла;
КонецЕсли;
конецесли;
возврат Новый Массив();
конецфункции
По умолчанию, Raspberry Pi работает с 1-wire на gpio-4, однако можно руками указать какой именно пин использовать для поиска устройств. Или несколько пинов сразу. Для этого нужно открыть файл /boot/firmware/connfig.txt и указать руками нужный пин:
dtoverlay=w1-gpio,gpiopin=24
Соответственно для того чтобы поиск шел на нескольких пинов: