Простой парсер таблицы в массив из HTML
Задача: необходимо преобразовать страницу HTML, в которой данные размещены в виде стандартной таблицы обрамленной тегами <table></table>, в двумерный массив на PHP (парсер таблицы в массив).
<table>
<tr>
<td>1</td><td>2</td><td>3</td><td>4</td>
</tr>
<tr>
<td>1</td><td>2</td><td>3</td><td>4</td>
</tr>
</table>Сначала я хотел решить задачу «в лоб», а именно искать теги в тексте, писать функционал по вычленению данных между тегами.. Но потом подумал, что «наверное всё уже придумано до нас», для подобных задач. Ну и собственно оказался прав. Задачу решил без лишних усилий в течении минут 5.
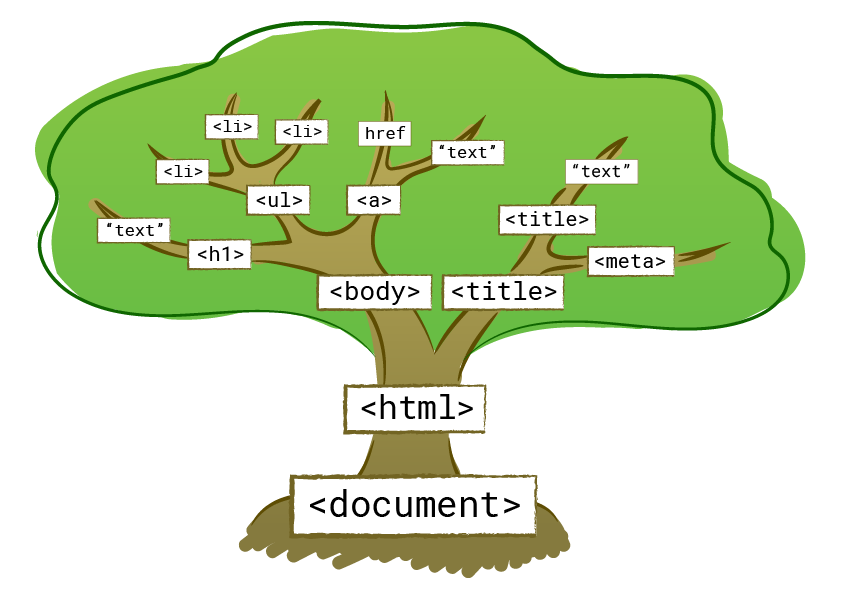
Решение: воспользуюсь PHP функцией DOMDocument для того чтобы преобразовать текст в DOM объект:
$contents = '<html lang="ru-RU"><head><meta charset="UTF-8" /></head><table>'.$contents."</table></html>";
$DOM = new DOMDocument;
$DOM->loadHTML($contents);Так я получаю построенное DOM дерево. Затем получаю все «ветки» по имени tr, и перебираю их, одновременно перебирая «всех листья» (т.е. тэги td):
function tdrows($elements){
$str = [];
foreach ($elements as $element) {$str[]= $element->nodeValue;}
return $str;
}
function getdata($contents){
$contents = '<html lang="ru-RU"><head><meta charset="UTF-8" /></head><table>'.$contents."</table></html>";
$DOM = new DOMDocument;
$DOM->loadHTML($contents);
$items = $DOM->getElementsByTagName('tr');
$mass=[];
foreach ($items as $node) {
$mass[]=tdrows($node->childNodes);
}
return $mass;
}
$mass=getdata($table);
var_dump($mass);Данные я передал в двухмерный массив $mass, т.е. задача «парсер таблицы в массив» решена
Ну а тут ссылка на подобную же задачу, но вместо HTML документа — файл формата XML