Создаём нейросеть на Python
Ну вот реально, очень мало в интернете статей на тему использования нейросетей. Теоретической информации — полно. «Напишем нейросеть в 9 строчек» — полно. А вот практических примеров с разжевыванием — единицы. Одна из хороших статей тут на хабре. Начало отличное, конец скомканный и до конца не раскрытый. Кроме того код во многих статьях датируемых до 20г уже не рабочий, т.к. используют Tensorflow версии меньше 2. Или ранние 2 версии. Посему на написание живого примера потратил довольно таки много времени.
Итак поставим себе задачу: узнать по фото, лето или зима отображены на ней.
Структура каталогов для датасета
Для начала создадим проект на python со следующей структурой каталогов:
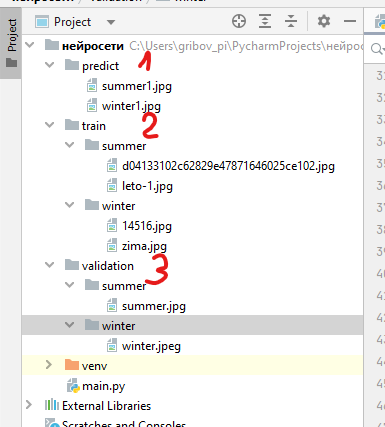
, где папки:
- predict (1) — сюда положим фотографии, по которым нейросеть будет давать ответ, лето там или зима
- tarin (2) — с двумя подпапками summer и winter, в которые разместим фотографии лета и осени для обучения нейросети. На скриншоте их всего 4, но этого конечно очень мало. Как минимум нужно пару тысяч для хорошего предсказания.
- validation (3) — валидационный набор фотографий — нужен для оценки качества обученной нейросети.
Необходимые для работы модули
Далее необходимо установить необходимые модули для Python для работы с нейросетью:
pip3 install tensorflow
pip3 install keras
pip3 install matplotlib
pip3 install numpy
pip3 install pillow
pip3 install imageРыба главного файла main.py
Создадим файл main,py со следующим содержимым:
import os
import tensorflow as tf
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as np
base_dir = os.path.dirname(os.path.abspath(__file__))
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_summer_dir = os.path.join(train_dir, 'summer')
train_winter_dir = os.path.join(train_dir, 'winter')
validation_summer_dir = os.path.join(validation_dir, 'summer')
validation_winter_dir = os.path.join(validation_dir, 'winter')
print("1. Готовимся к запуску")
print(f"- текущий каталог : {base_dir}")
print(f"-- каталоги изображений для тренировки : {validation_summer_dir},{train_winter_dir}")
print(f"-- каталоги изображений для проверки : {validation_summer_dir},{validation_winter_dir}")
num_summer_tr = len(os.listdir(train_summer_dir))
num_winter_tr = len(os.listdir(train_winter_dir))
num_summer_val = len(os.listdir(validation_summer_dir))
num_winter_val = len(os.listdir(validation_winter_dir))
total_train = num_summer_tr + num_winter_tr
total_val = num_summer_val + num_summer_val
print(f"--- картинок для тренировки {total_train}")
print(f"--- картинок для проверки {total_val}")
Фактически здесь мы сделали подготовительную работу, чтоб далее ни на что не отвлекаться при создании модели
Подготовка данных и установка параметров модели нейросети
Для того чтобы нейросеть могла обработать данные, их нужно привести к однообразному виду. Фоторафии бывают разного размера, разного цветового профиля и т.п. Для того чтобы привести их в примерно один и тот же формат и вид служит функция ImageDataGenerator |из пакета keras. Наиболее часто используемые параметры:
- rescale=1./255 — преобразует тензор (матрицу) изображений из интервалов значений 0..255 до 0..1 Зачем и какой механизм? У меня четкого понимания. Пока просто принимаю как данность, что необходимо при работе с изображениями.
- horizontal_flip=True — добавляет в тензор еще одно изображение, но отраженное по горизонтали
- rotation_range=xx — поворачивает изображение на xx градусов
- zoom_range=хх — увеличивает изображение
Последние параметры нужны для того чтобы нейросеть включала в модель обучения и слегка измененные изображения
print("2. Устанавливаем параметры модели")
BATCH_SIZE = 100 # количество тренировочных изображений для обработки перед обновлением параметров модели
IMG_SHAPE = 150 # размерность 150x150 к которой будет преведено входное изображение
# приведем изображение к градациям цвета 0.255 и зазеркалим, чтобы увеличить количество изображений для тренировки
train_image_generator = ImageDataGenerator(rescale=1./255, horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1./255)
print("- нормализуем все изображения для тренировки")
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE,IMG_SHAPE),
class_mode='binary')
Перед тем как изображения могут быть использованы в качестве входных данных для нашей сети их необходимо преобразовать к тензорам со значениями с плавающей запятой. Список шагов, которые необходимо предпринять для этого:
- Прочитать изображения с диска
- Декодировать содержимое изображений и преобразовать в нужный формат с учетом RGB-профиля
- Преобразовать к тензорам со значениями с плавающей запятой
- Произвести нормализацию значений тензора из интервала от 0 до 255 к интервалу от 0 до 1, так как нейронные сети лучше работают с маленькими входными значениями.
На выходе в переменную train_data_gen получим массив нормализованых изображений для тренировки. Проверочные изображения (которые используются для оценки качества обучения нейросети, тоже нормализцуем:
print("- нормализуем все изображения для проверки")
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=validation_dir,
shuffle=False,
target_size=(IMG_SHAPE,IMG_SHAPE),
class_mode='binary')
После того как мы определили генераторы для набора тестовых и валидационных данных, метод flow_from_directory загрузит изображения с диска, нормализует данные и изменит размер изображений — всего лишь одной строкой кода
При желании можно посмотреть, что у нас получилось:
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20, 20))
axes = axes.flatten()
for img, ax in zip(images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
augmented_images = [train_data_gen[0][0][0] for i in range(5)]plotImages(augmented_images)Добавим в модель слои
У модели должен быть обязательно входной слой, один или несколько промежуточных и один выходной слой. Кроме того необходимо задать количество нейронов сети, и количество классов на выходе.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), # входной слой
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(150, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(150, activation='relu'), # 150 нейронов
tf.keras.layers.Dense(2, activation='softmax') # 2- количество классов зима/лето
])Выпрямленная линейная функция активации или сокращенно ReLU (rectified linear activation unit) — это кусочно-линейная функция, которая выводит входные данные без изменений, если они положительные, и ноль, если входные данные отрицательные. Она стала функцией активации по умолчанию для многих типов нейронных сетей, потому что модель, использующую ее, легче обучать, и она часто достигает лучших результатов
Подробнее можно почитать например здесь
Рассмотрим подробнее что означает каждая строчка:
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), # входной слой- input_shape=(IMG_SHAPE, IMG_SHAPE, 3) — на входе изображение с размерами IMG_SHAPE х IMG_SHAPE, с 3 размерностью цветов (RGB)
- 32 — количество фильтров (каналов), фактически в моём понимании это количество признаков по которым могут отличаться изображения друг от друга
- (3,3) — размер ядра (окна внутри матрицы) в каждом фильтре. Выбираем исходя из того, насколько чувствительную модель мы хотим получить
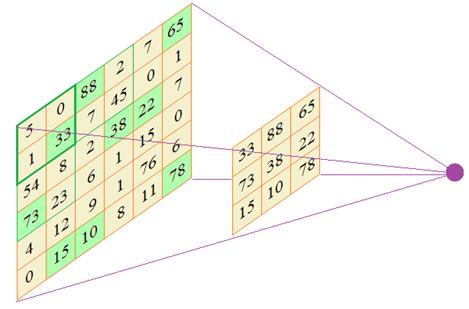
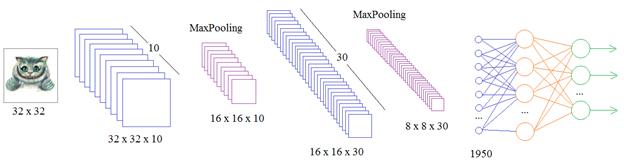
Как мы видим в итоге мы обьявили 4 слоя, с размерностью матрицы от 32х32 до 150х150. Т.е начинаем вычленять признаки на картинке уменьшеной до 32х32 и останавливаемся на вычленении признаков с размерами исходной картинки. Но можно и задать чуть больше, чтоб «бордюр» был.
Команда tf.keras.layers.MaxPooling2D(2, 2), говорит о том, что далее мы укрупняем масштаб полученых признаков. (2.2) — размер окна в котором выбирается максимальное значение
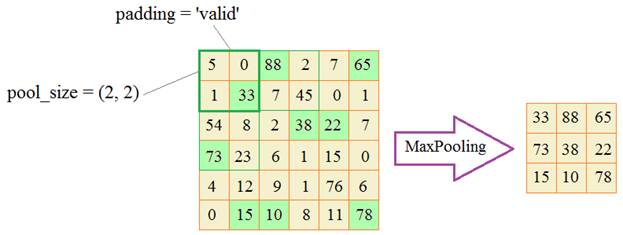
Команда tf.keras.layers.Dense(150, activation=’relu’), говорит что в работе будет задействовано 150 нейронов (по размеру матрицы)
Команда tf.keras.layers.Dense(2, activation=’softmax’), сообщает нейросети, что результат мы хотим получить в виде двух классов 0 — лето, 1 — зима (ну на входе для обучения у нас два вида картинок)
В пакете Keras можно найти слои:
Conv1D, Conv2D, Conv3D
так как на практике используют свертки для анализа одномерного, двумерного и трехмерного сигналов. Например, для:
- аудио – 1D (одномерный сигнал);
- изображения – 2D (двумерный сигнал);
- видео – 3D (трехмерный сигнал).
Компиляция модели
После того как данные по модели подготовили, её нужно «скомпилировать», указав алгоритм будущего обучения, и прочие параметры:
print("- скомпилируем модель, по алгоритму Адам")
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print("- представление модели:")
model.summary()
Мы воспользуемся оптимизатором adam. В качестве функции потерь воспользуемся sparse_categorical_crossentropy. Так же мы хотим на каждой обучающей итерации следить за точностью модели, поэтому передаём значение accuracy в параметр metrics.
Функция потерь — это мера того, насколько хорошо ваша модель прогнозирования предсказывает ожидаемый результат (или значение). Функция потерь также называется функцией затрат.
оптимизатор — это метод достижения лучших результатов, помощь в ускорении обучения. Другими словами, это алгоритм, используемый для незначительного изменения параметров, таких как веса и скорость обучения, чтобы модель работала правильно и быстро.
Помимо adam, есть еще ряд оптимизаторов: RMSprop, SGD и прочее. Чуть подробнее можно прочитать тут. Обычно таки для обработки изобращений используют adam.
Adam — один из самых эффективных алгоритмов оптимизации в обучении нейронных сетей. Он сочетает в себе идеи RMSProp и оптимизатора импульса. Вместо того чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. В частности, алгоритм вычисляет экспоненциальное скользящее среднее градиента и квадратичный градиент, а параметры beta1 и beta2 управляют скоростью затухания этих скользящих средних
Его преимущества:
- Простая реализация.
- Вычислительная эффективность.
- Небольшие требования к памяти.
- Инвариант к диагональному масштабированию градиентов.
- Хорошо подходит для больших с точки зрения данных и параметров задач.
- Подходит для нестационарных целей.
- Подходит для задач с очень шумными или разреженными градиентами.
- Гиперпараметры имеют наглядную интерпретацию и обычно требуют небольшой настройки.
Тренируем модель
Для тренировки модели необходимо выполнить код:
print("3. Тренируем модель")
EPOCHS = 10
history = model.fit(
train_data_gen,
steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))),
epochs=EPOCHS,
validation_data=val_data_gen,
validation_steps=int(np.ceil(total_val / float(BATCH_SIZE)))
)EPOCHS — это количество циклов обучения модели. Чем больше — тем лучше результат обучения. Подбирается экспериментальным путём.
Результат тренировки можно посмотреть в виде графиков:
print("4. Результаты тренировки")
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(8,8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Точность на обучении')
plt.plot(epochs_range, val_acc, label='Точность на валидации')
plt.legend(loc='lower right')
plt.title('Точность на обучающих и валидационных данных')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Потери на обучении')
plt.plot(epochs_range, val_loss, label='Потери на валидации')
plt.legend(loc='upper right')
plt.title('Потери на обучающих и валидационных данных')
plt.savefig('./foo.png')
plt.show()Проверка обученой модели
На этом шаге мы получили обученную модель. Теперь можно попробовать её попросить распознать, что же за изображение на картинке: Зима или лето? :
print("5. Узнаем по фото, что именно за картинка зима или лето..")
image = tf.keras.preprocessing.image.load_img(f"{base_dir}\\predict\\summer1.jpg", target_size=(IMG_SHAPE, IMG_SHAPE))
input_arr = tf.keras.preprocessing.image.img_to_array(image)
input_arr = np.array([input_arr])
input_arr = input_arr.astype('float32') / 255. # говорим что результат хотим число с плавающей запятой
predictions = model.predict(input_arr) # получаем результат проверки изображения в виде массива вероятностей
predicted_class = np.argmax(predictions, axis=-1) # вычленяем наиболее вероятный результат
print(predicted_class)Вывод в консоль может быть примерно такой:
5. Узнаем по фото, что именно за картинка зима или лето..
1/1 [==============================] - 0s 85ms/step
[0]Результат будет или 0 или 1, в зависимости от того что на картинке — лето или зима. Т.е. в зависисмости от количества классов.
Исходный код нейросети можно скачать здесь
Уведомление: Сохранение весов модели нейросети — ЖЗГ