1с: Работа с деревом значений
Задача: создать инструмент для распределения заявок по дням.
Решение: Наиболее удобным вариант я подумал что будет создание некого «дерева», узлами которого будут даты, а «ветвями» — заявки. Заявки можно будет перетаскивать между датами, тем самым равномерно распределяя нагрузку по дням.
Для того чтобы работать с деревьями, в 1С есть специальный тип: Дерево значений. Основной сущностностью у него являются строки. У каждой строки могут быть реквизиты (колонки). В то-же время каждая строка может иметь «потомков» — другие строки.
Создадим на форме «ДеревоОтключений» с типом «Дерево значений», и добавим у него реквизиты:
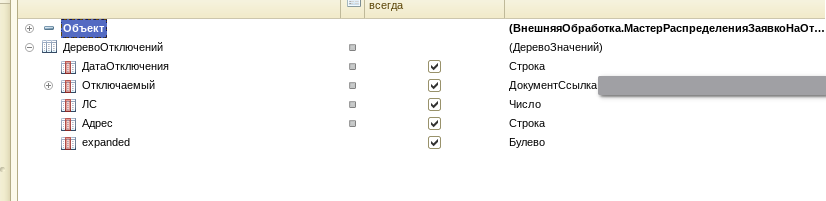
И перетащим его на форму. Далее по событию открытия, заполним дерево:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
ДО = РеквизитФормыВЗначение("ДеревоОтключений"); ДО.Строки.Очистить(); Для Счетчик = 0 По Число(Сред(КонецМесяца(объект.ПериодОтключения), 1, 2)) Цикл УДеньМесяца=ДО.Строки.Добавить(); если Счетчик=0 тогда УДеньМесяца.ДатаОтключения="не распределено"; иначе УДеньМесяца.ДатаОтключения=Формат(Дата(Год(объект.ПериодОтключения),Месяц(объект.ПериодОтключения),Счетчик),"ДФ=dd.MM.yyyy"); конецесли; УДеньМесяца.expanded=false; кол=0; для каждого стр из МассивОтключаемых[Счетчик] цикл ссср=УДеньМесяца.Строки.Добавить(); ссср.Отключаемый=стр; ссср.ЛС=Строка(стр.ЛС); ссср.Адрес=стр.АдресПотребителя; кол=кол+1; конеццикла; если кол>0 тогда УДеньМесяца.ЛС=Строка(кол); конецесли; КонецЦикла; ЗначениеВРеквизитФормы(ДО,"ДеревоОтключений"); |
Получаем такую чудную картинку:

Теперь осталось только запретить перетаскивание во все колонки кроме «ДатаОтключения», чтобы избежать «не правильных» деревьев. Для этого заполним событие «ПриПеретаскивании»:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
&НаКлиенте Процедура ДеревоОтключенийПеретаскивание(Элемент, ПараметрыПеретаскивания, СтандартнаяОбработка, Строка, Поле) //запретим если имя колонки куда тащим отличается от "ДатаОтключения" если Поле.Имя<>"ДеревоОтключенийДатаОтключения" тогда СтандартнаяОбработка=ложь; конецесли; //запретим если дата отключения пустая Куда=ДеревоОтключений.НайтиПоИдентификатору(Строка); если Куда.ДатаОтключения="" тогда СтандартнаяОбработка=ложь; конецесли; //запретим перетаскивание "в корень" если Куда.ДатаОтключения=ДеревоОтключений.НайтиПоИдентификатору(Элементы.ДеревоОтключений.ТекущаяСтрока).ПолучитьРодителя().ДатаОтключения тогда СтандартнаяОбработка=ложь; конецесли; КонецПроцедуры |
Для того чтобы обновить цифру с количеством «веток» в каждом узле, реализовал нечто подобное, разместив в событии «ОкончаниеПеретаскивания»:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
&НаКлиенте Процедура ДеревоОтключенийОкончаниеПеретаскивания(Элемент, ПараметрыПеретаскивания, СтандартнаяОбработка) ОбновляюКоличествоЛС(); КонецПроцедуры &НаКлиенте Функция ОбновляюКоличествоЛС() ЭлементыДерева = ДеревоОтключений.ПолучитьЭлементы(); для каждого стр из ЭлементыДерева цикл клв=стр.ПолучитьЭлементы().Количество(); если клв<50 тогда стр.ЛС=клв; конецесли; конеццикла; КонецФункции |
В рекруссию не пошел, т.к. в моём случае заведомо известно, что ветвей не более 1