Задача: есть некий справочник, к которому прикрепляются файлы. Физически они конечно хранятся в томах, но всё равно занимают места очень порядочно. Необходимо собственно каждый файлик положить в архив, заново «перекрепить» его к элементам справочника. Оригинал соответственно удалить.
Решение:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ ПЕРВЫЕ 1000
| Файлы.ВладелецФайла КАК ВладелецФайла,
| Файлы.Ссылка КАК Ссылка,
| Файлы.ПолноеНаименование КАК ПолноеНаименование,
| Файлы.ТекущаяВерсияПутьКФайлу КАК ПутьКФайлу,
| Файлы.ТекущаяВерсияТом.ПолныйПутьWindows КАК ПолныйПуть,
| Файлы.ДатаСоздания КАК ДатаСоздания
|ИЗ
| Справочник.Файлы КАК Файлы
|ГДЕ
| Файлы.ВладелецФайла ССЫЛКА Справочник.СК_ГосуслугиЛК_ВходящиеСообщения
| И Файлы.ПометкаУдаления = ЛОЖЬ
| И НЕ Файлы.ТекущаяВерсияПутьКФайлу ПОДОБНО ""%zip%""
| И Файлы.ДатаСоздания МЕЖДУ &ДатаС И &ДатаПо
|
|УПОРЯДОЧИТЬ ПО
| ДатаСоздания";
Запрос.УстановитьПараметр("ДатаС", объект.ДатаС);
Запрос.УстановитьПараметр("ДатаПо", объект.ДатаПо);
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
если СтрНайти(ВыборкаДетальныеЗаписи.ПутьКФайлу,".zip")=0 тогда
НовыйАрхив = Новый ЗаписьZipФайла(
ВыборкаДетальныеЗаписи.ПолныйПуть+"tmp.zip",
"","",МетодСжатияZIP.Сжатие,УровеньСжатияZIP.Максимальный,МетодШифрованияZIP.Zip20
);
НовыйАрхив.Добавить(ВыборкаДетальныеЗаписи.ПолныйПуть+ВыборкаДетальныеЗаписи.ПутьКФайлу);
НовыйАрхив.Записать();
//возврат 0;
ДвоичныеДанные = Новый ДвоичныеДанные(ВыборкаДетальныеЗаписи.ПолныйПуть+"tmp.zip");
АдресФайлаВХранилище = ПоместитьВоВременноеХранилище(ДвоичныеДанные);
РаботаСФайламиВызовСервера.СоздатьФайлСВерсией(
ВыборкаДетальныеЗаписи.ВладелецФайла,
ВыборкаДетальныеЗаписи.ПолноеНаименование+".zip",
"zip",
ТекущаяДата(),
ТекущаяДата(),
,
АдресФайлаВХранилище,АдресФайлаВХранилище,
Ложь,
,
,
Истина
);
об=ВыборкаДетальныеЗаписи.Ссылка.ПолучитьОбъект();
об.ПометкаУдаления=Истина;
об.Записать();
об.Удалить();
УдалитьФайлы(ВыборкаДетальныеЗаписи.ПолныйПуть+ВыборкаДетальныеЗаписи.ПутьКФайлу);
конецесли;
КонецЦикла;
Т.е. что тут делаем: выбираем элемент справочника с прикрепленным файлом, сжимаем его в архив zip, прикрепляем его и удаляем оригинал.
По умолчанию, не понятно почему на платформе не завезено средство сортировки таблицы значений отображаемой на форме. Поэтому выходом может быть например такое решение:
добавляем команды СортироватьПоКолонкеВозр и СортироватьПоКолонкеУбыв
добавляем их в контекстное меню
Код команды может быть такой:
&НаКлиенте
Процедура СортироватьПоКолонке(Команда)
ТЭ_имя_объект=ТекущийЭлемент.Имя;
ТЭ_поле=ТекущийЭлемент.ТекущийЭлемент.имя;
имяКолонки=СтрЗаменить( ТЭ_поле,ТЭ_имя_объект,"");
если команда.имя="СортироватьПоКолонкеУбыв" тогда
СортироватьНасервере(ТЭ_имя_объект,имяКолонки,"Убыв");
конецесли;
если команда.имя="СортироватьПоКолонкеВозр" тогда
СортироватьНасервере(ТЭ_имя_объект,имяКолонки,"Возр");
конецесли;
КонецПроцедуры
&НаСервере
Процедура сортироватьНасервере(имяОбъекта,имяКолонки,ВидСортировки)
тз= РеквизитФормыВЗначение("БуферТЗ");
тз.Сортировать(имяКолонки+" "+ВидСортировки);
ЗначениеВРеквизитФормы(ТЗ,"БуферТЗ");
конецпроцедуры
Задача: из формы документа открыть форму подбора чего-либо, и по результату получить результат в исходную форму.
Ну собственно задача штатная и обыденная, никаких изобретений тут нет. Оставляю, т.к. не часто этим пользуюсь и забывается
Решение:
В исходной форме вызываем новую форму:
&НаКлиенте
Процедура ПодборФИАС(Команда)
Оповещение = Новый ОписаниеОповещения("ПолучитьФИАСДомаИзФормыПодбора", ЭтотОбъект);
ПараметрыФормы = Новый Структура;
ПараметрыФормы.Вставить("Ключ", объект.Ссылка);
ОткрытьФорму("Справочник.УКАУКАУК.Форма.ФормаПодбораФИАС", ПараметрыФормы,ЭтаФорма,,,,Оповещение,РежимОткрытияОкнаФормы.БлокироватьВесьИнтерфейс);
КонецПроцедуры
&НаКлиенте
Функция ПолучитьФИАСДомаИзФормыПодбора(Результат, ДополнительныеПараметры) экспорт
нс=объект.Дома.Добавить();
нс.ИдДома="-";
нс.КодФиас=Результат.ВыбранныйФиас;
КонецФункции
В открываемой форме, пропишем обработку закрытия формы:
&НаКлиенте
Процедура ПередЗакрытием(Отказ, ЗавершениеРаботы, ТекстПредупреждения, СтандартнаяОбработка)
Фиас="";
для каждого стр из Элементы.Дом.СписокВыбора цикл
если стр.Представление=Элементы.Дом.ВыделенныйТекст тогда
Фиас=стр.Значение;
конецЕсли;
конеццикла;
ПараметрыЗакрытия = Новый Структура;
ПараметрыЗакрытия.Вставить("ВыбранныйФиас", Фиас);
Закрыть(ПараметрыЗакрытия);
КонецПроцедуры
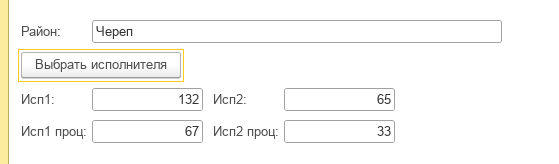
Задача: есть два исполнителя. Необходимо обеспечить, чтобы исполнителю №1 доставалось 2/3 заявок, и исполнителю №2 — 1/3 задач.
Решение: высчитывать какому исполнителю сколько перепало уже заявок и в каком порядке, мне показалось излишним. Тем более, если думать на перспективу, то скорее всего окажется что потом будет добавлено еще несколько исполнителей со своими долями. Поэтому был реализован следующий алгоритм выбора исполнителя:
Исполнитель 1, с долями 2/3
Исполнитель 2, с долями 1/3
Как вычисляем исполнителя:
Всего долей: 3
— Создаем кость, с гранями 1,2,3
— Грани 1 и 2 = Исполнитель 1
— Грань 3 = Исполнитель 2
Кидаем «кость». Какая грань выпадет, такой исполнитель и назначается. В принципе при достаточном количестве бросков, процентное соотношение выпадений исполнителя выходит:
Исполнитель 1: 67%
Исполнитель 2: 33 %
Ну и кому интересно, вот код реализации:
&НаСервере
Функция ВыбратьИсполнителяНаСервере()
Наименование=объект.Район;
нама=СтрРазделить(Наименование," ");
Район=ВРег(нама[0]);
Исполнители=Новый Массив();
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ДоступВЛКДляКонтрагентаРайоныОбслуживания.Ссылка.Ссылка КАК Ссылка,
| ДоступВЛКДляКонтрагентаРайоныОбслуживания.Доля КАК Доля
|ИЗ
| Справочник.ДоступВЛКДляКонтрагента.РайоныОбслуживания КАК ДоступВЛКДляКонтрагентаРайоныОбслуживания
|ГДЕ
| ВРЕГ(ДоступВЛКДляКонтрагентаРайоныОбслуживания.Район.Наименование) ПОДОБНО &Наименование";
Запрос.УстановитьПараметр("Наименование", "%"+Район+"%");
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
ВсегоДолей=0;
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
Исполнители.Добавить(Новый Структура("исполнитель,доля",ВыборкаДетальныеЗаписи.Ссылка,ВыборкаДетальныеЗаписи.Доля));
ВсегоДолей=ВсегоДолей+ВыборкаДетальныеЗаписи.Доля;
КонецЦикла;
Если Исполнители.Количество()=0 тогда
возврат неопределено;
конецесли;
// если исполнитель один, то с долями не морочимся
Если Исполнители.Количество()=1 тогда
Возврат Исполнители[0].исполнитель;
конецесли;
// если всего долей 0, а исполнителей более чем 1, то тогда исполнитель - первый попавшийся
если ВсегоДолей=0 тогда
Возврат Исполнители[0].исполнитель;
конецесли;
// А вот тут уже мудрим с долями
ЗаполненныеДоли=Новый Массив();
для каждого исполнитель из Исполнители цикл
для поз=1 по исполнитель.доля цикл
ЗаполненныеДоли.Добавить(исполнитель.исполнитель);
конеццикла
конеццикла;
// Здесь уже имеем массив с заполненными развернутыми исполнителями. Например: Вася,Вася,Вася,Петя,Петя
// Осталось сгенерировать случайное число 1-5, и назначить в соответствии с выпавшим числом исполнителя
Генератор = Новый ГенераторСлучайныхЧисел(ТекущаяУниверсальнаяДатаВМиллисекундах());
СлучайноеЧисло = Генератор.СлучайноеЧисло(0,ЗаполненныеДоли.Количество()-1);
Возврат ЗаполненныеДоли[СлучайноеЧисло];
КонецФункции